Simulate a World Cup Group in Python: From Team Strengths to Advancement Odds
Turn four teams' strengths into the odds each one survives the group.
A World Cup group is a small, self-contained drama: four teams, six matches, three matchdays, and one question that hangs over all of it — who goes through? In 2026 each of the twelve groups sends its top two straight into the round of 32, with the eight best third-placed teams also surviving, so the stakes inside a single group are sharper than ever. You cannot replay the real thing, but you can replay a model of it ten thousand times in a fraction of a second. This tutorial builds that simulator in Python, turning four teams' attack and defence strengths into each side's probability of advancing.
How a 2026 group works
The format facts are settled, even though not a single match has been played yet. The 2026 World Cup expands to 48 teams in 12 groups of four. Within a group, every team plays the other three once — six matches in all — and earns three points for a win, one for a draw, none for a loss. The top two of every group qualify automatically for the round of 32, and the eight best third-placed teams across all twelve groups join them. That third-place math is its own puzzle, worked through in the best third-place qualification math; for this tutorial we keep things clean and simulate the question every group shares — the probability of finishing top two.
One honesty note up front, because it matters. As of this writing the tournament has not kicked off. The team names and strength numbers in the code below are an invented, clearly-labelled toy set, chosen only so the script runs end to end. They are not the real 2026 field, not based on any draw, and not a prediction of anyone. To get meaningful output you supply your own ratings; the machinery does not change.
The model: Poisson goals
To simulate a match we need to turn two teams into a scoreline. The standard tool is the Poisson model, which treats each team's expected goals in a fixture as the mean of a Poisson distribution and draws a random goal count from it. We derive that model from first principles in build a Poisson goals model in Python; here we use it as a building block. Each team gets an attack rating and a defence rating expressed relative to an average of 1.0 — attack above 1 means a better-than-average scorer, defence below 1 means a meaner-than-average back line.
The expected goals for one side in a fixture come from multiplying its attack by the opponent's defence and a baseline goals-per-team figure. There is no home advantage at a World Cup group stage in the usual sense — matches are at neutral venues — so we drop the home/away split and use a single baseline.
λ(team B) = attack(B) × defence(A) × baseline goals
import numpy as np
from scipy.stats import poisson
rng = np.random.default_rng(42)
# --- TOY TEAMS (invented, NOT the real 2026 field) ----------------
# Replace with your own attack/defence ratings (~1.0 = average).
# attack: higher = scores more. defence: lower = concedes less.
GROUP = {
"Falcons": {"attack": 1.45, "defence": 0.80},
"Wolves": {"attack": 1.15, "defence": 0.95},
"Cranes": {"attack": 1.00, "defence": 1.05},
"Stallions":{"attack": 0.80, "defence": 1.30},
}
BASELINE_GOALS = 1.35 # league/tournament average goals per team per game
def expected_goals(att_team, def_team):
"""Two Poisson means for a neutral-venue fixture."""
lam_a = GROUP[att_team]["attack"] * GROUP[def_team]["defence"] * BASELINE_GOALS
lam_b = GROUP[def_team]["attack"] * GROUP[att_team]["defence"] * BASELINE_GOALS
return lam_a, lam_b
That helper is the whole engine. Everything else is bookkeeping: which matches to play, how to score them, and how to rank four teams once the goals are in.
Playing all six matches
A four-team group has exactly six pairings — every unordered pair of distinct teams. Python's itertools.combinations generates them in one line. For each pairing we draw a random scoreline from the two Poisson means and award points: three to the winner, one to each side on a draw.
from itertools import combinations
from collections import defaultdict
def play_group(seed_rng):
"""Simulate all six matches once. Returns points, GF, GA per team."""
pts = defaultdict(int)
gf = defaultdict(int)
ga = defaultdict(int)
for team_a, team_b in combinations(GROUP, 2):
lam_a, lam_b = expected_goals(team_a, team_b)
goals_a = seed_rng.poisson(lam_a)
goals_b = seed_rng.poisson(lam_b)
gf[team_a] += goals_a; ga[team_a] += goals_b
gf[team_b] += goals_b; ga[team_b] += goals_a
if goals_a > goals_b:
pts[team_a] += 3
elif goals_b > goals_a:
pts[team_b] += 3
else:
pts[team_a] += 1; pts[team_b] += 1
return pts, gf, ga
Ranking with tiebreakers
Points alone rarely settle a four-team group; ties are common over just three games each. The real competition uses a defined ladder of tiebreakers, and we mirror its spirit with a sort key: points first, then goal difference, then goals scored. (FIFA's full ladder adds head-to-head results and, ultimately, fair-play points and drawing of lots, but points, goal difference and goals scored resolve the overwhelming majority of cases and keep the code readable.) Python sorts ascending, so we negate each criterion to sort best-first.
def rank_group(pts, gf, ga):
"""Return teams ordered best-to-worst by pts, GD, GF."""
def key(team):
goal_diff = gf[team] - ga[team]
return (-pts[team], -goal_diff, -gf[team])
return sorted(GROUP, key=key)
One subtlety worth naming: when two teams are genuinely identical on all three criteria, the real tournament breaks the tie with rules we are not modelling, whereas our sort leaves their order to chance. Over many simulations that washes out, but it is the kind of honest gap between a toy and the real rulebook worth keeping in mind.
Monte Carlo: ten thousand groups
A single simulated group tells you almost nothing — it is one roll of the dice. The power comes from repetition. Replay the group thousands of times, record where each team finishes, and the share of runs in which a team lands in the top two is its estimated advancement probability. This is exactly the engine behind a full bracket, which we scale up in how a World Cup simulation works.
def simulate(n_sims=10_000, seed=42):
rng = np.random.default_rng(seed)
finishes = {t: np.zeros(4, dtype=int) for t in GROUP} # count by position
advance = defaultdict(int) # top-2 counts
for _ in range(n_sims):
pts, gf, ga = play_group(rng)
order = rank_group(pts, gf, ga)
for position, team in enumerate(order):
finishes[team][position] += 1
advance[order[0]] += 1 # winner
advance[order[1]] += 1 # runner-up
print(f"Advancement odds (top 2) over {n_sims:,} simulations:\n")
for team in sorted(GROUP, key=lambda t: -advance[t]):
p_adv = advance[team] / n_sims
p_win = finishes[team][0] / n_sims
print(f" {team:9s} advance {p_adv:5.1%} win group {p_win:5.1%}")
simulate()
Run it and you get a clean table: each team's probability of escaping the group and, as a bonus, its chance of topping it. Because the toy ratings make Falcons clearly the strongest and Stallions clearly the weakest, the output will rank them in roughly that order — but the gaps between the middle teams, and the fact that even the favourite does not advance 100% of the time, are the genuinely interesting part. Short groups are noisy, and the simulation quantifies exactly how noisy.
Making it your own
Three extensions turn this from a demo into a real tool. First, swap the toy dictionary for actual ratings: a sensible source is a power-rating system, and soccer power ratings: Elo, SPI, and why they disagree explains how to convert one number per team into the attack and defence strengths this model wants. Second, raise n_sims to 50,000 or more for tighter estimates — the cost is trivial. Third, track third place too, so you can feed the eight-best-thirds calculation; the rule is laid out in the best third-place qualification math, and the broader tournament context lives in World Cup 2026 by the numbers.
From here the natural next step is the knockout stage. Once your twelve groups have produced their thirty-two survivors, build a knockout bracket simulator in Python takes those teams and plays the bracket out to a champion — and the same Poisson scoreline engine you wrote here can power those matches too.
Sources & further reading
- Free textbook: Chapter 20: Predictive Modeling — the theory behind this, at DataField.dev.
- SciPy documentation — reference for
scipy.stats.poissonand the random sampling used throughout. - StatsBomb open data — match results you can use to estimate real attack and defence strengths for your teams.
- FBref — international results and scoring records for building rating inputs.
- StatsBomb — background on modelling goals and match outcomes.
More from World Cup 2026
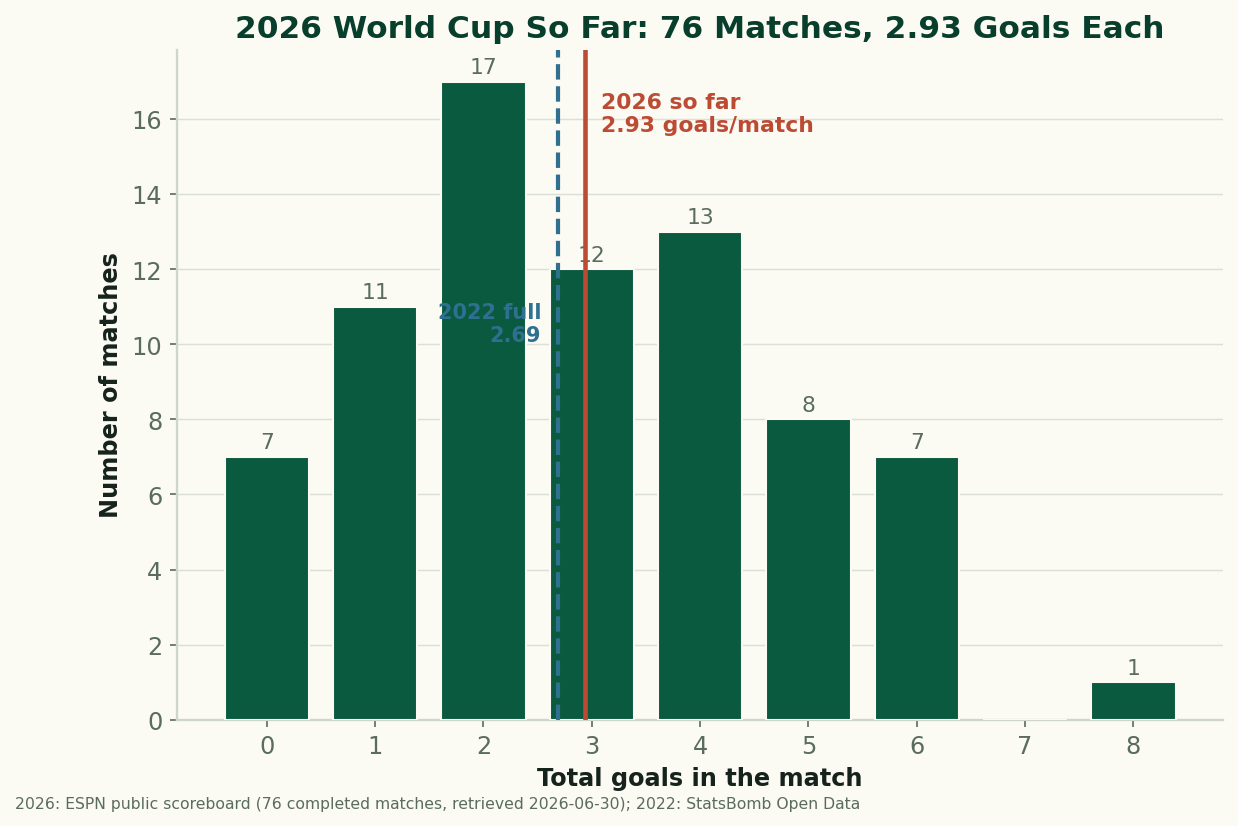
The 2026 World Cup So Far, By the Numbers: Just Under 3 Goals a Game
Through 76 completed matches, the 2026 World Cup is still outscoring 2022 — 2.93 goals a game to 2.69. After an early spike the rate has settled just under 3 a game. The real, sourced numbers on goals, draws, and the blowouts behind them, with honest caveats about a group-stage-only sample. (A living snapshot, refreshed as games are played.)
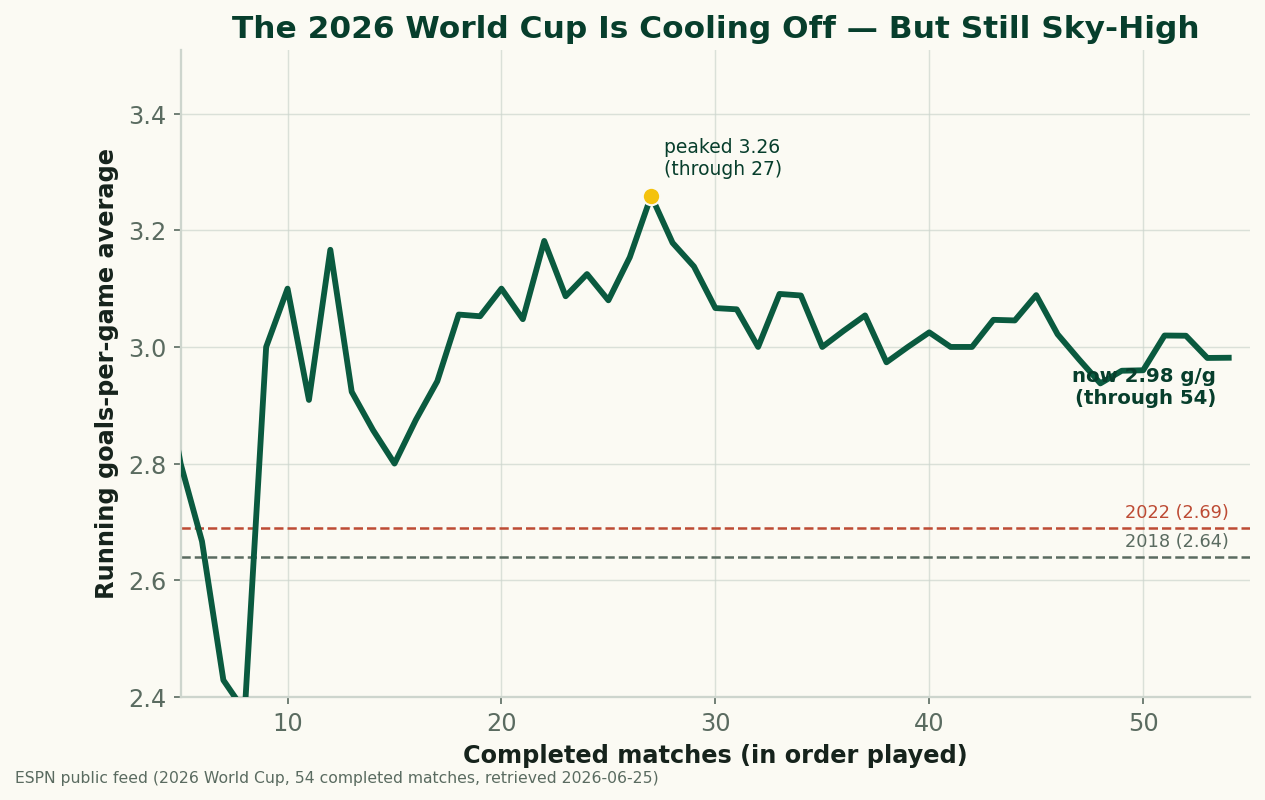
The 2026 World Cup Is Cooling Off — and Still the Highest-Scoring in Generations
Through 54 completed matches, the 2026 World Cup is averaging 2.98 goals a game — down from a blistering 3.26 early on, but still comfortably above 2022 (2.69) and 2018 (2.64), and the highest-scoring World Cup since 1970. A refreshed look at where the goals are going as the group stage closes.
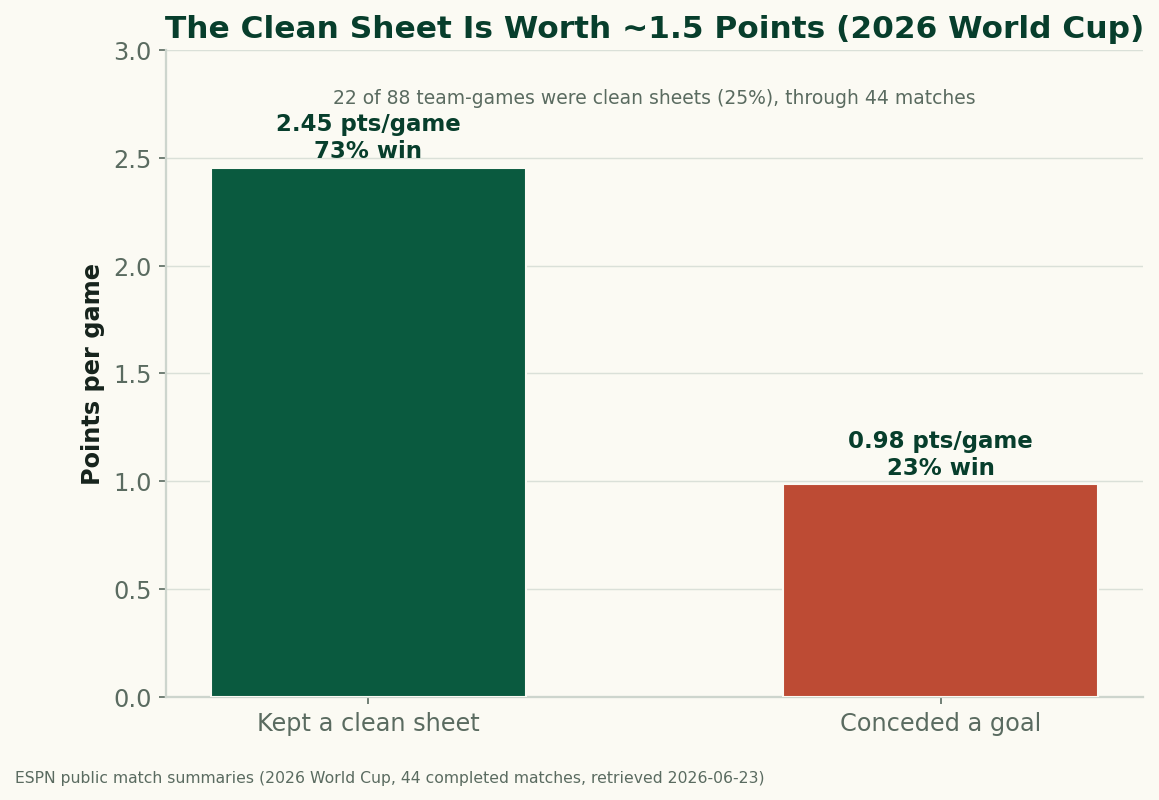
The Clean Sheet Is the Most Valuable Thing at the 2026 World Cup
Through 44 completed matches, a team that keeps a clean sheet at the 2026 World Cup averages 2.45 points and wins 73% of the time; a team that concedes averages under 1. Don't concede and you almost can't lose — the data on what a clean sheet is worth.