How a World Cup Simulation Works
Play the whole tournament fifty thousand times, then count.
When a forecaster says a team has, say, a one-in-eight chance of winning the World Cup, they did not derive it from an equation. They built a model of the tournament, played the entire thing from group stage to final, recorded who won, and then did it again tens of thousands of times. The team's title probability is simply the fraction of those simulated tournaments it won. This is the Monte Carlo method, it is how essentially every serious World Cup forecast is produced, and understanding it tells you exactly why two careful models can disagree about the favourite.
Why you cannot just calculate it
It is tempting to think title odds should come from a formula — multiply the probability of winning the group by the probability of winning each knockout round. The problem is that those probabilities are not independent or fixed. Who a team meets in the round of 16 depends on which teams top their groups, which depends on results that have not happened; a kind path can open or a brutal one can close based on a single upset three games earlier. The bracket is a tree of contingencies, and the clean way to handle a tree of contingencies is not to solve it analytically but to sample it: play it out, let the contingencies resolve themselves, and repeat until the averages stabilise.
The two ingredients
A simulation needs exactly two things. The first is a rating for every team — a strength estimate, whether a single Elo figure or a paired attack-and-defence number in the SPI tradition. Where those come from, and why reasonable people build them differently, is covered in soccer power ratings: Elo, SPI and why they disagree and how models rate the field before a World Cup is played.
The second is a match model that turns two ratings into the result of a single game. The workhorse is a Poisson model: convert the rating gap (plus any venue adjustment) into an expected number of goals for each side, then treat each team's goals as a draw from a Poisson distribution. That yields a probability for every scoreline, and therefore for a win, draw or loss. We build precisely this engine, step by step, in the Poisson goals model in Python, and explain its place in forecasting in how win-probability models work.
Walking through a single run
One simulated tournament proceeds exactly as the real one would. Each group fixture is played by sampling a scoreline from the match model, and the points are tallied. The group tables are sorted — with tiebreakers applied as the competition rules specify — and the qualifying teams advance into the knockout bracket. Each knockout tie is then sampled in turn; because knockouts cannot end level, a tie that the model lands on as a draw is pushed to extra time and, if needed, a shoot-out, which most simulations treat as close to 50/50 between two teams of any strength. Eventually one team is left standing, and the simulation notes the champion, the finalists, the semi-finalists, and so on.
That single run is almost meaningless on its own — it is one possible tournament, dominated by the luck of the draws it happened to sample. The power comes from repetition. Run it 50,000 times and the noise averages out: a team that won 6,000 of those runs gets a 12% title probability, and every other question — reach the semis, top the group, suffer a group-stage exit — is answered the same way, by counting the fraction of simulations in which it occurred.
Why the number is a range, not a fact
Two competent modellers can run this identical procedure and publish different favourites. The disagreement does not come from the simulation engine — that part is mechanical — but from the inputs, and a handful of choices dominate.
The ratings. The biggest lever. A results-only Elo and a chance-quality-aware hybrid can rate the same team meaningfully differently, and because the match model is non-linear, a modest rating gap can swing a title share by several points. This is the same compounding sensitivity that makes club projections diverge, dissected in why league projection models disagree.
The home and venue edge. How much advantage to give host or near-host teams, and how to handle travel, altitude and heat across a continent-spanning tournament, is a real and unsettled choice — see altitude and heat at the 2026 venues and the general magnitude in home advantage, quantified. A model that bakes in a large host edge will tilt its whole distribution toward those teams.
The shoot-out assumption. Treating shoot-outs as pure coin flips versus giving a small edge to the stronger side, or to teams with documented preparation, nudges the deep-run odds of every contender. The case that shoot-outs are partly trainable is made in preparing for penalties.
Variance settings. How much randomness the match model injects controls how often upsets happen. A higher-variance model produces more chaos and flatter odds; a lower-variance one concentrates probability on the favourites. Neither is obviously right, and the choice shows up directly in how open the field looks.
Reading a simulation honestly
The output of a Monte Carlo run is genuinely useful — it is a coherent, internally consistent map of how a tournament could unfold, and it correctly captures things human intuition mangles, like the value of a kind draw or the brutal arithmetic of needing seven straight results. But it is a map drawn from assumptions, not a measurement of the future. The right way to use two such forecasts is the way we recommend for league models: when they agree, that is relative confidence; when they diverge, one of them has made a different, examinable assumption about ratings, home edge, or variance. The honest takeaway is to read the spread across models as the real uncertainty, and to distrust any single decimal that claims to know the winner of a tournament that, by its nature, the best team loses more often than not. For how all of this frames the expanded field, start with World Cup 2026 by the numbers.
Sources & further reading
- Free textbook: Chapter 20: Predictive Modeling — the theory behind this, at DataField.dev.
- StatsBomb — event data and research underpinning chance-quality ratings and match models.
- FBref — international results and xG, the inputs a simulation's ratings are trained on.
- ClubElo — a transparent rating system whose published method shows the kind of choices that drive simulation disagreement.
- FIFA — official tournament format, group structure and knockout bracket rules that a simulation must encode.
More from World Cup 2026
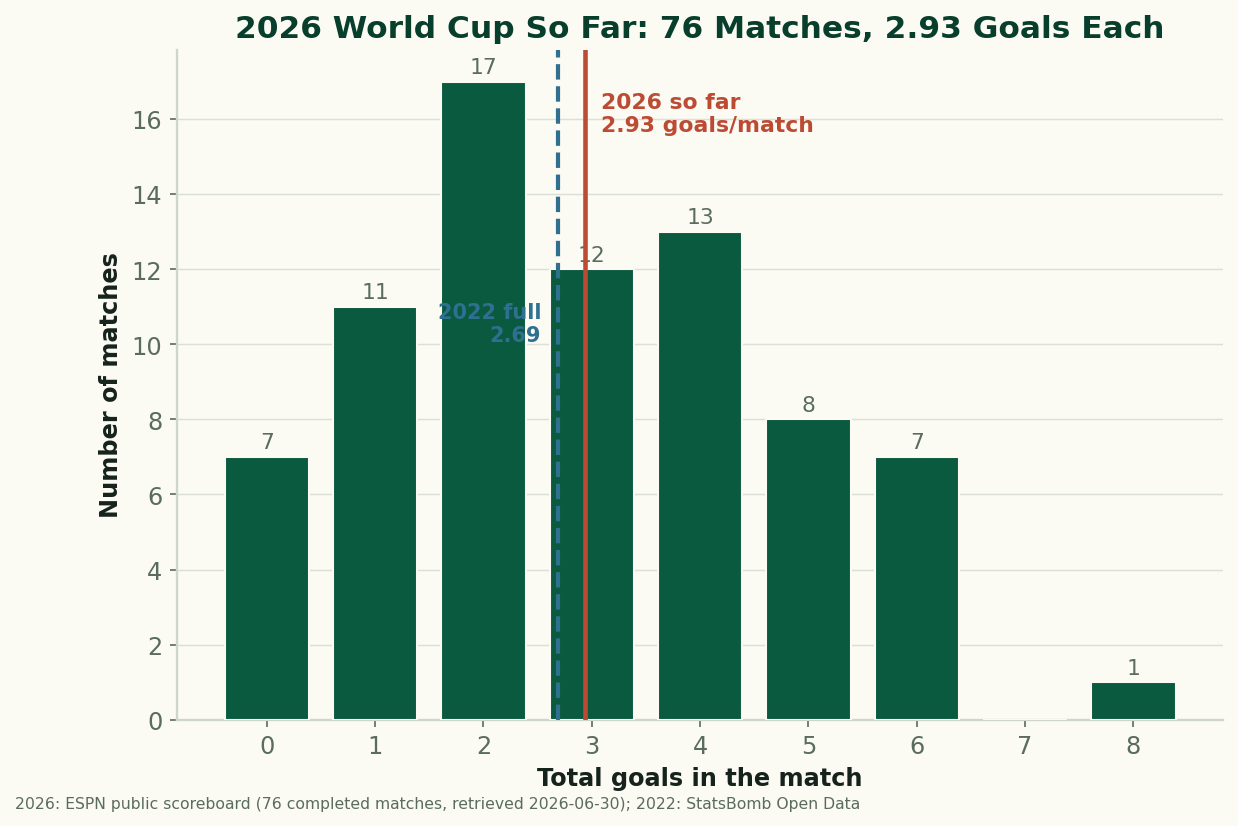
The 2026 World Cup So Far, By the Numbers: Just Under 3 Goals a Game
Through 76 completed matches, the 2026 World Cup is still outscoring 2022 — 2.93 goals a game to 2.69. After an early spike the rate has settled just under 3 a game. The real, sourced numbers on goals, draws, and the blowouts behind them, with honest caveats about a group-stage-only sample. (A living snapshot, refreshed as games are played.)
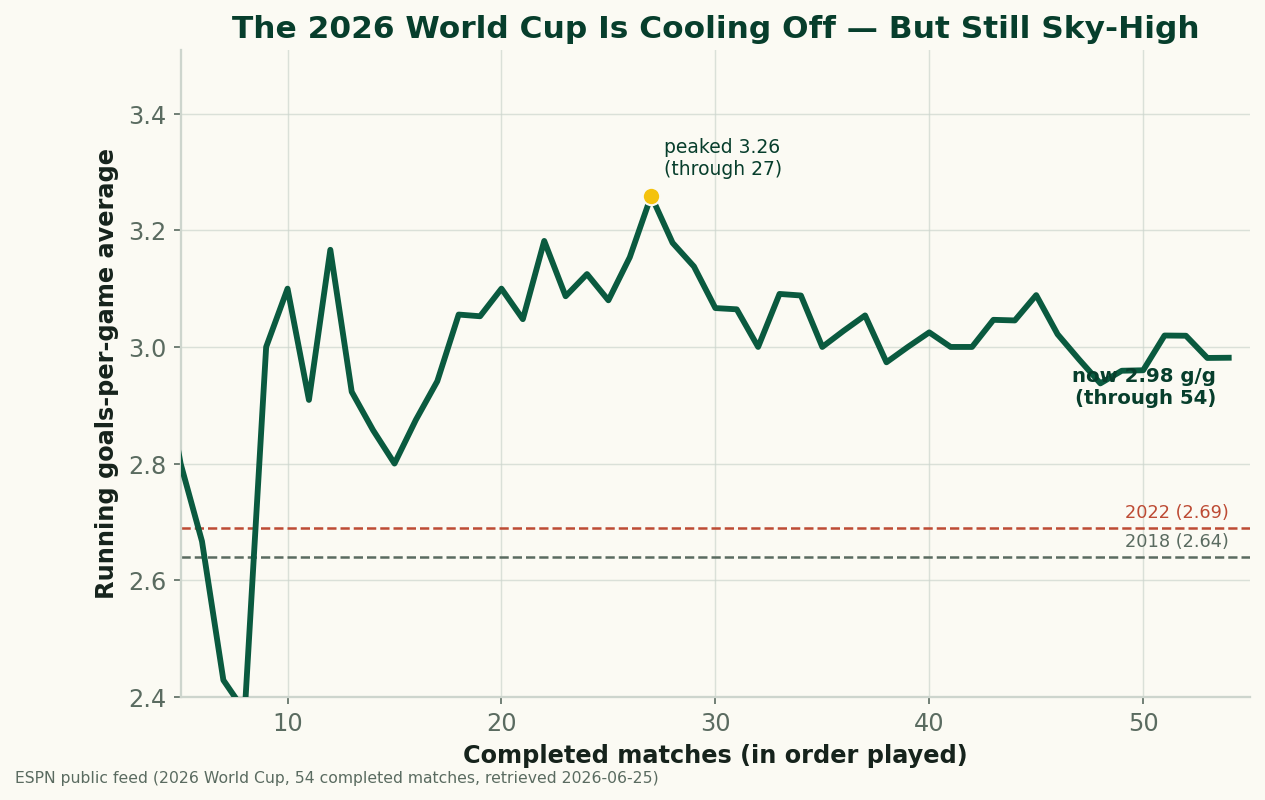
The 2026 World Cup Is Cooling Off — and Still the Highest-Scoring in Generations
Through 54 completed matches, the 2026 World Cup is averaging 2.98 goals a game — down from a blistering 3.26 early on, but still comfortably above 2022 (2.69) and 2018 (2.64), and the highest-scoring World Cup since 1970. A refreshed look at where the goals are going as the group stage closes.
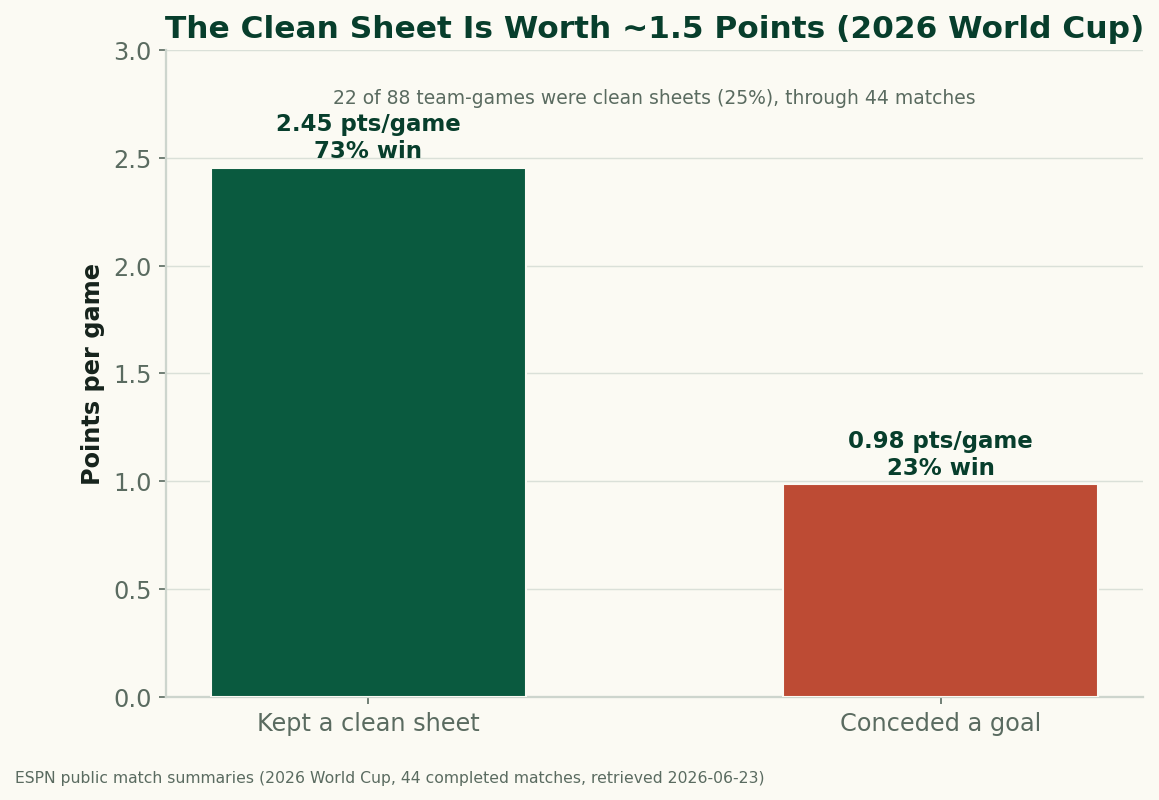
The Clean Sheet Is the Most Valuable Thing at the 2026 World Cup
Through 44 completed matches, a team that keeps a clean sheet at the 2026 World Cup averages 2.45 points and wins 73% of the time; a team that concedes averages under 1. Don't concede and you almost can't lose — the data on what a clean sheet is worth.